Amazon Redshift Integration
Integration of Amazon Redshift with Entropy Data.
The Amazon Redshift integration is managed within Entropy Data. Configure the connection and sync schedule to start syncing with Amazon Redshift.
No additional deployments are needed.
Features
- Asset Synchronization: Sync schemas, tables, and columns from Amazon Redshift to Entropy Data as Assets.
- Query Execution: Execute read-only SQL queries on Redshift data products through the MCP interface and Entropy Intelligence.
Prerequisites
You need an Entropy Data Enterprise License or the Cloud Edition. To enable the integration, set APPLICATION_INGESTIONS_ENABLED to true in your environment. See Configuration for more information.
To start, navigate to Settings > Integrations > Add Integration.
This opens a wizard that guides you through configuring the integration.
Configuration
Select the Integration Type
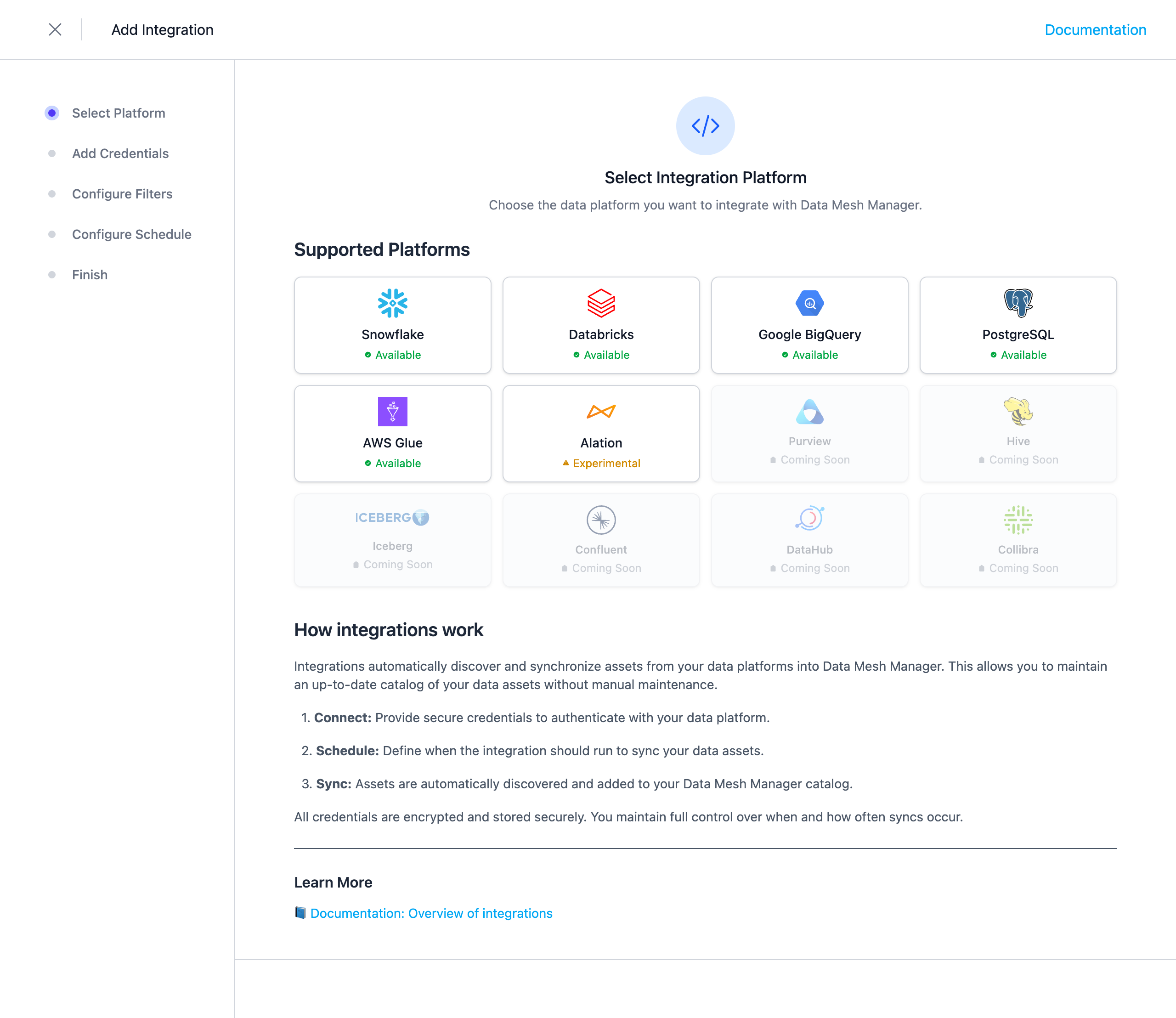 Select Amazon Redshift from the list of available integrations.
Select Amazon Redshift from the list of available integrations.
Configure the Credentials
The integration uses the AWS Redshift Data API with IAM credentials for authentication. Both Redshift Serverless (workgroups) and provisioned clusters are supported.
Refer to the AWS documentation for creating a new access key. While creating the access key, select the use case 'Other'.
The IAM user or role associated with the access key needs permissions for the Redshift Data API and access to the Redshift cluster or workgroup. You may use the following AWS policy to grant them:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"redshift-data:ExecuteStatement",
"redshift-data:DescribeStatement",
"redshift-data:GetStatementResult",
"redshift-serverless:GetCredentials"
],
"Resource": "*"
}
]
}
For provisioned clusters, additionally grant:
{
"Effect": "Allow",
"Action": "redshift:GetClusterCredentialsWithIAM",
"Resource": "arn:aws:redshift:*:*:dbname:*/*"
}
Provide the following connection details:
| Parameter | Description |
|---|---|
| AWS Region | The AWS region where your Redshift cluster or workgroup is located (e.g., eu-central-1) |
| Cluster Identifier | The identifier of your provisioned Redshift cluster (leave empty for Serverless) |
| Workgroup Name | The name of your Redshift Serverless workgroup (leave empty for provisioned clusters) |
| Database | The name of the database to connect to (e.g., dev) |
| Database User | The database user for query execution (provisioned clusters only, optional) |
| AWS Access Key ID | The IAM access key ID (starts with AKIA) |
| AWS Secret Access Key | The corresponding secret access key |
| AWS Session Token | Optional session token for temporary credentials (e.g., from STS AssumeRole) |
Note: Credentials are stored encrypted in the Entropy Data database. To enable encryption in your environment, set a 64 hex character
APPLICATION_ENCRYPTION_KEYSin your environment (see Configuration).
Configure Filters
Configure filters to limit which assets are synchronized. Both include and exclude filters are supported. For Amazon Redshift, filters can be applied to Schemas and Tables.
Filters support '*' as a wildcard character to match any number of characters.
Configure Schedule
Set a schedule to automatically synchronize assets. You can choose from predefined schedules or define a custom schedule using the cron expression format.
Note: All schedules use the UTC timezone, so make sure to take this into account when configuring your schedule. Please do not synchronize the assets more than once or twice per day. We reserve the right to disable the integration if this happens. You will be able to trigger a synchronization manually if you need an immediate update.
Complete the Integration Configuration
Choose a unique name for the integration, review your configuration, and click Create Integration.
Query Execution
Once the integration is configured, users can execute read-only SQL queries against Redshift data products through:
- MCP Interface: Use the
execute_querytool to run SQL queries on Redshift output ports. - Entropy Intelligence: Chat-based query execution with automatic connection setup.
To execute queries, each user needs to configure a personal Redshift connection in their profile under Connections. This ensures queries run on behalf of the individual user with their own AWS credentials and permissions.
Next Steps
The integration is now configured and will run according to the schedule. To check the integration status, navigate to Settings > Integrations. Here you'll find the current status and the last 10 integration runs.
You can adjust the integration configuration and credentials at any time. The configuration is saved in YAML format with syntax validation support in the editor.
Note: The previously stored credentials are not displayed in the edit view for security reasons. If you want to change them, add new credentials and save the integration.
Deselecting the Enabled checkbox disables the automatic schedule. Manual integration runs are still possible.